Evaluation Protocols¶
A central feature of CausalWorld is the explicit parametric formulation of environments that allow for a precise evaluation of generalization capabilities with respect to any of the defining environment variables.
In order to evaluate a certain generalization aspect an evaluation protocol needs to be defined. Each evaluation protocol defines a set of episodes that might differ from each other with respect to the generalisation aspect under consideration.
If e.g. the agent is evaluated regarding success under different masses each episodes is a counterfactual version of the other with the mass of a certain object being the only difference.
After the given set of environments in a protocol are being evaluated, various aggregated success metrics are being computed based on the fractional reward profiles of each episode.
Each of the environments variables has two associated sets of accessible non-overlapping spaces: A and B. When a space is activated for the CausalWorld Object during training or evaluation all the variables will only be allowed to take values within that space, though they generally wont visit the entire space spanned.
Example¶
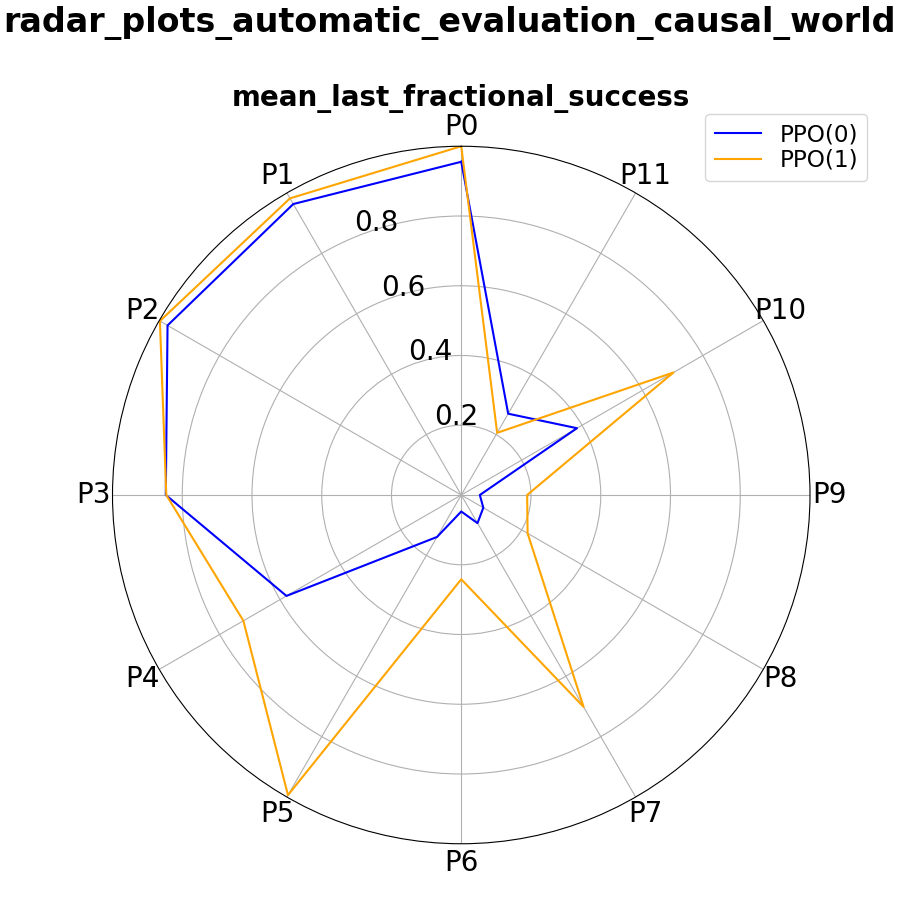
As an introductory example we want to show you how you can quantify different generalization aspects depending on the curriculum exposed during training using the pushing task.
We trained two different agents: First, on the default task only without any type of randomization applied between episodes. This means the agent always starts with the same initial tool_block pose and the same goal block pose. Naturally we expect the agent to overfit to this goal over time.
Second, we train an agent using a goal randomization curriculum where we sample new goal poses within space A every episode. Still, we keep the initial tool_block poses and everything else fixed during training.
As can be seen from the animation below we see that the former agent overfits to the single goal pose seen during training whereas the later can also push the tool block towards other goal poses.
Evaluating both agents using the protocols defined in the pushing benchmark we can quantify and compare performance regarding different aspects in an explicit way.


Using default protocols¶
Below we show some demo code how you can systematically evaluate agents on a set of different protocols and visualize the results in radar plots of different scores
"""
This tutorial shows you how to train a policy and evaluate it afterwards using
an evaluation pipeline compromised of different evaluation protocols.
"""
from causal_world.task_generators.task import generate_task
from causal_world.envs.causalworld import CausalWorld
from stable_baselines import PPO2
from stable_baselines.common.policies import MlpPolicy
import tensorflow as tf
tf.compat.v1.logging.set_verbosity(tf.compat.v1.logging.ERROR)
import os
from stable_baselines.common import set_global_seeds
from stable_baselines.common.vec_env import SubprocVecEnv
from causal_world.evaluation.evaluation import EvaluationPipeline
import causal_world.evaluation.protocols as protocols
log_relative_path = './pushing_policy_tutorial_1'
def _make_env(rank):
def _init():
task = generate_task(task_generator_id="pushing")
env = CausalWorld(task=task, enable_visualization=False, seed=rank, skip_frame=3)
return env
set_global_seeds(0)
return _init
def train_policy():
ppo_config = {
"gamma": 0.9988,
"n_steps": 200,
"ent_coef": 0,
"learning_rate": 0.001,
"vf_coef": 0.99,
"max_grad_norm": 0.1,
"lam": 0.95,
"nminibatches": 5,
"noptepochs": 100,
"cliprange": 0.2,
"tensorboard_log": log_relative_path
}
os.makedirs(log_relative_path)
policy_kwargs = dict(act_fun=tf.nn.tanh, net_arch=[256, 128])
env = SubprocVecEnv([_make_env(rank=i) for i in range(5)])
model = PPO2(MlpPolicy,
env,
_init_setup_model=True,
policy_kwargs=policy_kwargs,
verbose=1,
**ppo_config)
model.learn(total_timesteps=1000,
tb_log_name="ppo2",
reset_num_timesteps=False)
model.save(os.path.join(log_relative_path, 'model'))
env.env_method("save_world", log_relative_path)
env.close()
return
def evaluate_trained_policy():
# Load the PPO2 policy trained on the pushing task
model = PPO2.load(os.path.join(log_relative_path, 'model.zip'))
# define a method for the policy fn of your trained model
def policy_fn(obs):
return model.predict(obs)[0]
# pass the different protocols you'd like to evaluate in the following
evaluator = EvaluationPipeline(evaluation_protocols=[
protocols.FullyRandomProtocol(name='P11', variable_space='space_b')],
visualize_evaluation=True,
tracker_path=log_relative_path,
initial_seed=0)
# For demonstration purposes we evaluate the policy on 10 per cent of the default number of episodes per protocol
scores = evaluator.evaluate_policy(policy_fn, fraction=0.05)
evaluator.save_scores(log_relative_path)
print(scores)
if __name__ == '__main__':
train_policy()
evaluate_trained_policy()
"""
This tutorial shows you how to train a policy and evaluate it afterwards using
one of the default evaluation benchmarks.
"""
from causal_world.evaluation.evaluation import EvaluationPipeline
from causal_world.benchmark.benchmarks import REACHING_BENCHMARK
from causal_world.task_generators.task import generate_task
from causal_world.envs.causalworld import CausalWorld
import causal_world.evaluation.visualization.visualiser as vis
from stable_baselines import PPO2
from stable_baselines.common.policies import MlpPolicy
import tensorflow as tf
tf.compat.v1.logging.set_verbosity(tf.compat.v1.logging.ERROR)
import os
from stable_baselines.common import set_global_seeds
from stable_baselines.common.vec_env import SubprocVecEnv
log_relative_path = './pushing_policy_tutorial_2'
def _make_env(rank):
def _init():
task = generate_task(task_generator_id="reaching")
env = CausalWorld(task=task, enable_visualization=False, seed=rank)
return env
set_global_seeds(0)
return _init
def train_policy():
ppo_config = {
"gamma": 0.9988,
"n_steps": 200,
"ent_coef": 0,
"learning_rate": 0.001,
"vf_coef": 0.99,
"max_grad_norm": 0.1,
"lam": 0.95,
"nminibatches": 5,
"noptepochs": 100,
"cliprange": 0.2,
"tensorboard_log": log_relative_path
}
os.makedirs(log_relative_path)
policy_kwargs = dict(act_fun=tf.nn.tanh, net_arch=[256, 128])
env = SubprocVecEnv([_make_env(rank=i) for i in range(5)])
model = PPO2(MlpPolicy,
env,
_init_setup_model=True,
policy_kwargs=policy_kwargs,
verbose=1,
**ppo_config)
model.learn(total_timesteps=1000,
tb_log_name="ppo2",
reset_num_timesteps=False)
model.save(os.path.join(log_relative_path, 'model'))
env.env_method("save_world", log_relative_path)
env.close()
return
def evaluate_model():
# Load the PPO2 policy trained on the reaching task
model = PPO2.load(os.path.join(log_relative_path, 'model.zip'))
# define a method for the policy fn of your trained model
def policy_fn(obs):
return model.predict(obs)[0]
# Let's evaluate the policy on some default evaluation protocols for reaching task
evaluation_protocols = REACHING_BENCHMARK['evaluation_protocols']
evaluator = EvaluationPipeline(evaluation_protocols=evaluation_protocols,
tracker_path=log_relative_path,
initial_seed=0)
# For demonstration purposes we evaluate the policy on 10 per cent of the default number of episodes per protocol
scores = evaluator.evaluate_policy(policy_fn, fraction=0.1)
evaluator.save_scores(log_relative_path)
experiments = {'reaching_model': scores}
vis.generate_visual_analysis(log_relative_path, experiments=experiments)
if __name__ == '__main__':
#first train the policy, skip if u already trained the policy
train_policy()
evaluate_model()
"""
This tutorial shows you how to train a policy and evaluate it afterwards using
one of the default evaluation benchmarks.
"""
from causal_world.evaluation.evaluation import EvaluationPipeline
from causal_world.benchmark.benchmarks import PUSHING_BENCHMARK
from causal_world.task_generators.task import generate_task
from causal_world.envs.causalworld import CausalWorld
import causal_world.evaluation.visualization.visualiser as vis
from stable_baselines import PPO2
from stable_baselines.common.policies import MlpPolicy
import tensorflow as tf
tf.compat.v1.logging.set_verbosity(tf.compat.v1.logging.ERROR)
import os
from stable_baselines.common import set_global_seeds
from stable_baselines.common.vec_env import SubprocVecEnv
log_relative_path = './pushing_policy_tutorial_3'
def _make_env(rank):
def _init():
task = generate_task(task_generator_id="pushing")
env = CausalWorld(task=task, enable_visualization=False, seed=rank)
return env
set_global_seeds(0)
return _init
def train_policy():
ppo_config = {
"gamma": 0.9988,
"n_steps": 200,
"ent_coef": 0,
"learning_rate": 0.001,
"vf_coef": 0.99,
"max_grad_norm": 0.1,
"lam": 0.95,
"nminibatches": 5,
"noptepochs": 100,
"cliprange": 0.2,
"tensorboard_log": log_relative_path
}
os.makedirs(log_relative_path)
policy_kwargs = dict(act_fun=tf.nn.tanh, net_arch=[256, 128])
env = SubprocVecEnv([_make_env(rank=i) for i in range(5)])
model = PPO2(MlpPolicy,
env,
_init_setup_model=True,
policy_kwargs=policy_kwargs,
verbose=1,
**ppo_config)
model.learn(total_timesteps=1000,
tb_log_name="ppo2",
reset_num_timesteps=False)
model.save(os.path.join(log_relative_path, 'model'))
env.env_method("save_world", log_relative_path)
env.close()
return
def evaluate_model():
# Load the PPO2 policy trained on the pushing task
model = PPO2.load(os.path.join(log_relative_path, 'model.zip'))
# define a method for the policy fn of your trained model
def policy_fn(obs):
return model.predict(obs)[0]
# Let's evaluate the policy on some default evaluation protocols for reaching task
evaluation_protocols = PUSHING_BENCHMARK['evaluation_protocols']
evaluator = EvaluationPipeline(evaluation_protocols=evaluation_protocols,
tracker_path=log_relative_path,
initial_seed=0)
# For demonstration purposes we evaluate the policy on 10 per cent of the default number of episodes per protocol
scores = evaluator.evaluate_policy(policy_fn, fraction=0.02)
evaluator.save_scores(log_relative_path)
experiments = {'pushing_model': scores}
vis.generate_visual_analysis(log_relative_path, experiments=experiments)
if __name__ == '__main__':
#first train the policy, skip if u already trained the policy
train_policy()
evaluate_model()